How search engines like Google work.
By Frank McCown © 2009-2012
Abstract
This article examines at a high level some of the major technical aspects involved in how web search engines discover web pages, index the content, and provide search results.Introduction
In 2008, Google reported that they had discovered over 1 trillion unique URLs on the Web [1]. And as previous research has shown [2], it is unlikely that Google, or any other search engine, is even close to discovering all the available content on the Web. The Web is certainly a large place, and finding information can be a daunting task without a web search engine. In this article, we will examine how search engines work by examining the collection process, indexing of the content, and the factors that play in ranking the content.Web Directories
In 1994, the Web was a much smaller place. Stanford graduate students Jerry Yang and David Filo started manually organizing their favorite websites into a directory which soon became the foundation of Yahoo! [3]. A web directory allows you to find web pages based on navigating a structured hierarchy. For example, Computers and Internet > Internet > World Wide Web > History would lead you to a set of websites about the Web’s history.Although hierarchical classifications of web pages can be helpful, this is not always the ideal way to find information on the Web. For example, if you wanted to know who founded Yahoo!, it would be time consuming to search through the hierarchy of web pages and then scan each page for the information you were seeking. Creating human-powered web directories is also not a scalable strategy as the Web continues to grow and change at a fantastic rate.
To provide search functionality for the Web, search engines must first discover what the web pages actually say and then create an index on the page contents. The index can then be quickly searched to reveal which pages contain the given query text.
Web Crawling
Matthew Gray’s World Wide Web Wanderer (1993) was one of the first efforts to automate the discovery of web pages [4]. Gray’s web crawler would download a web page, examine it for links to other pages, and continue downloading links it discovered until there were no more links left to be discovered. This is how web crawlers, also called spiders, generally operate today.Because the Web is so large, search engines normally employ thousands of web crawlers that meticulously scour the web day and night, downloading pages, looking for links to new pages, and revisiting old pages that might have changed since they were visited last. Search engines will often revisit pages based on their frequency of change in order to keep their index fresh. This is necessary so search engine users can always find the most up-to-date information on the Web.
Maintaining an accurate "snap shot" of the Web is challenging, not only because of the size of the Web and constantly changing content, but also because pages disappear at an alarming rate (a problem commonly called linkrot). Brewster Kahle, founder of the Internet Archive, estimates that web pages have an average life expectancy of only 100 days [5]. And some pages cannot be found by web crawling. These are pages that are not linked to others, pages that are password-protected or are generated dynamically when submitting a web form. These pages reside in the deep Web, also called the hidden or invisible Web [6].
Some website owners don’t want their pages indexed by search engines for any number of reasons, so they use the Robots Exclusion Protocol (robots.txt) to tell web crawlers which URLs are off-limits. Other website owners want to ensure certain web pages are indexed by search engines, so they use the Sitemap Protocol, a method supported by all major search engines, to provide a crawler with a list of URLs they want indexed [7]. Sitemaps are especially useful in providing the crawler URLs it would be unable to find with web crawling.
Figure 1 below shows how a web crawler pulls from the Web and places downloaded web resources into a local repository. The next section will examine how this repository of web resources is then indexed and retrieved when you enter a query into a search engine.

|
| Figure 1 - The Web is crawled and placed into a local repository where it is indexed and retrieved when using a search engine. |
Indexing and Ranking
When a web crawler has downloaded a web page, the search engine will index its content. Often the stop words, words that occur very frequently like a, and, the, and to, are ignored. Other words might be stemmed. Stemming is a technique that removes suffixes from a word to improve the content of the index. For example, eating, eats, and eaten may all be stemmed to eat so that a search for eat will match all its variants.An example index (usually called an inverted index) will look something like this where the number corresponds to a web page that contains the text:
cat > 2, 5
dog > 1, 5, 6
fish > 1, 2
bird > 4
So a query for dog would result in pages 1, 5, and 6. A query for cat dog would only result in page 5 since it is the only page that contains both search terms. Some search engines provide advanced search capabilities, so a search for cat OR dog and NOT fish would be entered which would result in pages 1, 5, and 6.
The search engine also maintains multiple weights for each term. The weight might correspond to any number of factors that determines how relevant the term is to its host web page. Term frequency is one such weight which measures how often a term appears in a web page. For example, if someone wanted to search the Web for pages about dogs, a web page containing the term dog five times would likely be more relevant than a page containing dog just once. However, term frequency is susceptible to spamming (or spamdexing), a technique which some individuals use to artificially manipulate a web page’s ranking, so it is only one of many factors which are used [8].
Another weight that is given to a web page is based on the context in which the term appears in the page. If the term appears in a large, bold font or in the title of the page, it may be given more weight than to a term that appears in a regular font. A page might also be given more weight if links pointing to the page use the term in its anchor text. In other words, a page that is pointed to with the link text “see the dogs” is more likely about dogs since the term dogs appears in the link. This functionality has left search engines susceptible to a practice known as Google-bombing, where many individuals collude to produce the same anchor text to the same web page for humorous effect. A popular Google bomb once promoted the White House website to the first result when searching Google for “miserable failure”. Google has recently implemented an algorithmic solution capable of diffusing most Google bombs [9].
A final weight which most search engines will use is based on the web graph, the graph which is created when viewing web pages as nodes and links as directed edges. Sergey Brin and Larry Page were graduate students at Stanford University when they noted just how important the web graph was in determining the relevancy of a web page. In 1998, they wrote a research paper [10] about how to measure the importance of a web page by examining a page’s position in the web graph, in particular the page’s in-links (incoming links) and out-links (outgoing links). Essentially, they viewed links like a citation. Good pages receive many citations, and bad pages receive few. So pages that have in-links from many other pages are probably more important and should rank higher than pages that few people link to. Weight should also be given to pages based on who is pointing to them; an in-link from a highly cited page is better than an in-link from a lowly cited page. Brin and Page named their ranking algorithm PageRank, and it was instrumental in popularizing their new search engine called Google. All search engines today take into account the web graph when ranking results.
Figure 2 shows an example of a web graph where web pages are nodes and links from one page to another are directed edges. The size and color of the nodes indicate how much PageRank the web pages have. Note that pages with high PageRank (red nodes) generally have significantly more in-links than do pages with low PageRank (green nodes).
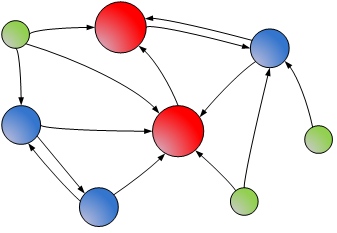 |
| Figure 2 – Example web graph. Pages with higher PageRank are represented with larger nodes. |
Rank Optimization
Search engines guard their weighting formulas as a trade secret since it differentiates their service from other search engines, and they do not want content-producers (the public who produces web pages) to “unfairly” manipulate their rankings. However, many companies rely heavily on search engines for recommendations and customers, and their ranking on a search engine results page (SERP) is very important. Most search engine users only examine the first screen of results, and they view the first few results more often than the results at the bottom of the page. This naturally pits content-producers in an adversarial role against search engines since the producers have an economic incentive to rank highly in SERPs. Competition for certain terms (e.g., Hawaii vacation and flight to New York) is particularly fierce. Because of this, most search engines provide paid-inclusion or sponsored results along with regular (organic) results. This allows companies to purchase space on a SERP for certain terms.An industry based on search engine optimization (SEO) thrives on improving their customer’s rankings by designing their pages to maximize the various weights discussed above and to increase the number and quality of incoming links. Black hat SEOs may use a number of questionable techniques like spamdexing and link farms, artificially created web pages designed to bolster the PageRank of a particular set of web pages, to increase their ranking. When detected, such behavior is often punished by search engines by removing the pages from their index and embargoing the website for a period of time [11].
Vertical Search
Search engines like Google, Yahoo!, and Bing normally provide specialized types of web search called vertical search [12]. A few examples include:- Regular web search is the most popular type of search which searches the index based on any type of web page. Other on-line textual resources like PDFs and Microsoft Office formats are also available through regular web search.
- News search will search only news-related websites. Typically the search results are ordered based on age of the story.
- Image search searches only images that were discovered when crawling the web. Images are normally indexed by using the image’s filename and text surrounding the image. Artificial intelligence techniques for trying to discover what is actually pictured in the image are slowly emerging. For example, Google can now separate images of faces and line drawing from other image types.
- Video search searches the text accompanied by videos on the Web. Like image search, there is heavy reliance on people to supply text which accurately describes the video.
Other specialty searches include blog search, newsgroup search, scholarly literature search, etc. Search engines also occasionally mix various types of search results together onto the same SERP. Figure 3 below shows how Ask.com displays news and images along with regular web search results when searching for harding. The blending of results from different vertical search offerings is usually called universal search [13].
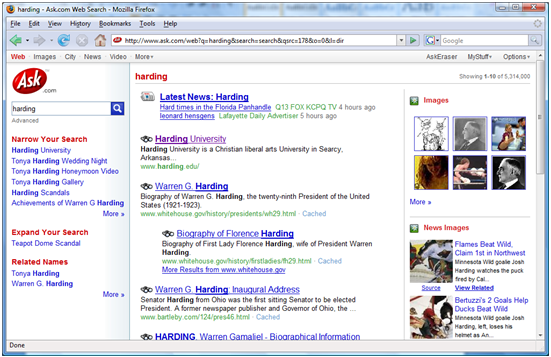 |
| Figure 3 - Ask.com's universal search results. |
Personalized Search
In order to provide the best possible set of search results for a searcher, many search engines today are experimenting with techniques that take into account personal search behavior. When searching for leopard, a user who often queries for technical information is more likely to want to see results dealing with Leopard the operating system than leopard the animal. Research has also shown that one third of all queries are repeat queries, and most of the time an individual will click on the same result they clicked on before [14]. Therefore a search engine should ideally present the previously-selected result close to the top of the SERP when recognizing the user has entered the same query before.Figure 4 below shows a screen shot of personalized search results via Google's SearchWiki [15], an experiment in search personalization that Google rolled-out in late 2008. The user was able to promote results higher in the list, remove poor results from the list, and add comments to specific results. The comment and removal functions are no longer available today, but Google does allow users to star results that they like, and these starred results appear prominently when the user later searches for the same content.
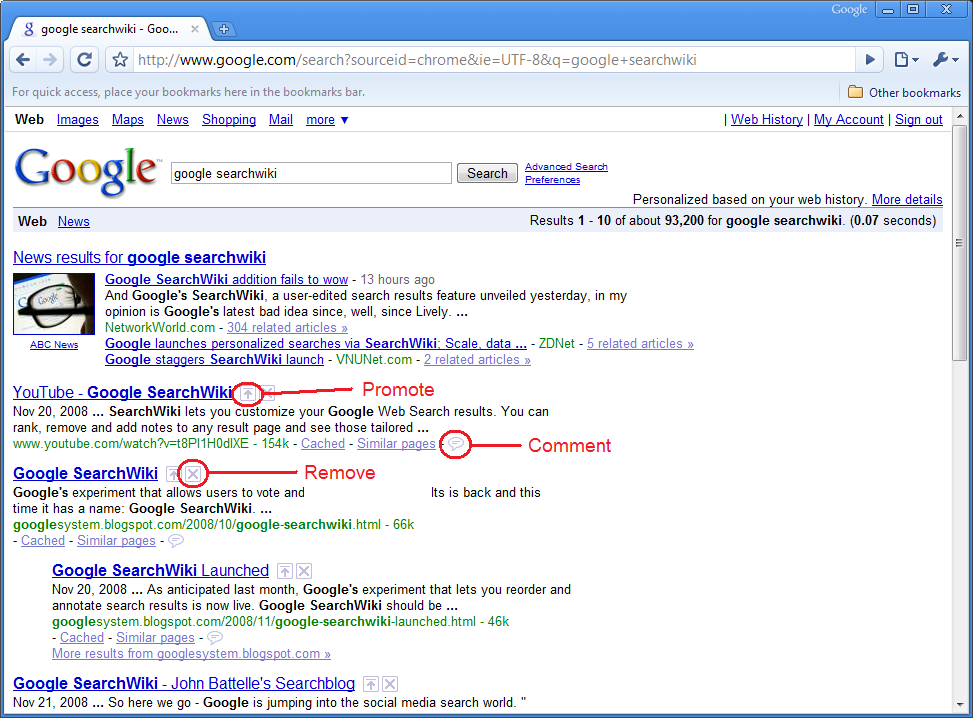
Figure 4 – Example
of Google's SearchWiki.
As smartphones have become increasingly popular, search engines have started providing search results based on the user's location [15]. A location-aware search engine recognizes that when a user searches for restaurants on their mobile device, they are likely wanting to find restaurants in their near vicinity.
Conclusions
Searching the entire Web in less than a second is a substantial engineering achievement. As we have seen, search engines are not searching the live Web but instead the copies of web pages that it has previously crawled. Pages are ranked based on their physical characteristics (title, term frequency, font size, etc.) and on their level of connectivity in the Web graph. The competition to present the most relevant set of search results is fierce, and search engines are always looking for better search mechanisms and altering how results are presented. The competition for ranking #1 is also fierce, guaranteeing the practice of SEO will not die anytime soon.References
- We knew the web was big...
http://googleblog.blogspot.com/2008/07/w e-knew-web-was-big.h tml - Gulli, Antonio and Signorini,Alessio (2005). The indexable web is more than 11.5 billion pages. In Proceedings of WWW 2005.
http://www.cs.uiowa.edu/~asignori/web-si ze/ - The History of Yahoo! - How It All Started...
http://docs.yahoo.com/info/misc/history. html - Measuring the Growth of the Web
http://www.mit.edu/people/mkgray/growth/ - Weiss, Rick.: On the web, research work proves ephemeral: Electronic archivists are playing catch-up in trying to keep documents from landing in history's dustbin (2003). The Washington Post.
http://www.washingtonpost.com/ac2/wp-dyn /A8730-2003Nov23 - Bergman, Michael K. (August 2001). "The Deep Web: Surfacing Hidden Value". The Journal of Electronic Publishing 7 (1).
http://dx.doi.org/10.3998/3336451.0007.1 04 - Sitemaps.org
http://www.sitemaps.org/ - Gyöngyi, Zoltán and Garcia-Molina, Hector (2005), "Web spam taxonomy", Proceedings of the First International Workshop on Adversarial Information Retrieval on the Web (AIRWeb), 2005
http://airweb.cse.lehigh.edu/2005/gyongy i.pdf - A quick word about Googlebombs
http://googlewebmastercentral.blogspot.c om/2007/01/quick-wor d-about-googlebombs. html - Brin, Sergey and Page, Lawrence (1998), The Anatomy of a Large-Scale Hypertextual Web Search Engine
http://infolab.stanford.edu/~backrub/goo gle.html - Cutts, Matt. Ramping up on international webspam (Feb 2006)
http://www.mattcutts.com/blog/ramping-up -on-international-we bspam/ - Watch Out Google, Vertical Search Is Ramping Up!
http://www.readwriteweb.com/archives/ver tical_search.php - Universal search: The best answer is still the best answer
http://googleblog.blogspot.com/2007/05/u niversal-search-best -answer-is-still.htm l - Teevan, Jaime, Adar, Eytan, Jones, Rosie, and Potts, Michael (2006). History repeats itself: repeat queries in Yahoo's logs. In Proceedings of SIGIR '06.
http://doi.acm.org/10.1145/1148170.11483 26 - SearchWiki: make search your own
http://googleblog.blogspot.com/2008/11/s earchwiki-make-searc h-your-own.html - Harnick Chris (2009). How location-based searches are changing mobile, Mobile Marketer.
http://www.mobilemarketer.com/cms/news/search/3994.html